
Whatever the scale of the event of disaster, downtime is downtime—and failure to have an adequate DR plan in place threatens your business’s ability to keep ticking along as it should. Essentially, the need to maintain business continuity is the driving force behind disaster recovery, a critical point to keep in mind as you approach building out a DR plan.
More SMBs Embracing DR
As the need for DR grows in importance, many SMBs who may have once dismissed it are now jumping on board. Cloud technology has played a big role in this, which we’ll cover in the next section. The need for DR is also driven by the competitive pressures of today’s manufacturing marketplace. Regardless of size, no company can afford to be the weak link in a highly connected chain of customers and suppliers. And when unplanned downtime does occur, it’s often small businesses who have the hardest time recovering. Consider the following unsettling statistics for SMBs:
The Adoption of Cloud Technology
It wasn’t too long ago that the adoption of cloud technology was characterized by a cautious wait-and-see attitude, rife with perceived risks and unknowns. Today, of course, there’s been a dramatic shift in that attitude. Manufacturing companies are quick to embrace all things cloud, viewing “as-a-service” technologies as the most viable and secure option for their needs—and Disaster Recovery as a Service (DRaaS) is no exception.
DRaaS has exploded into the market in the last few years, breaking down many of the traditional barriers companies once faced when considering a DR plan, such as lack of budget and lack of resources. DRaaS has opened the doors for SMBs everywhere, making DR implementation easier, more accessible and often more cost-effective. DRaaS solutions essentially eliminate the need for large cash outlays for equipment, and they can be implemented quickly and without need for complex IT infrastructure. They can also promise ready-to-go communication to multiple locations, faster testing times and fewer personnel requirements, as compared to managing everything in-house.
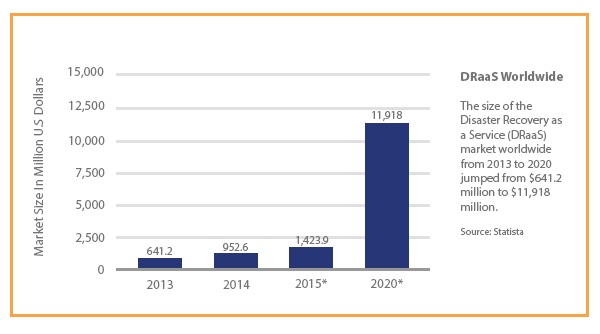
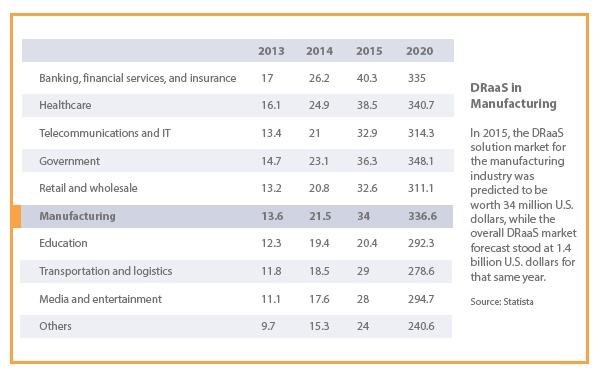
The Global Growth of DRaaS in Manufacturing
While some organizations still have success in implementing and managing their DR efforts in house, or with a “DIY” approach, the greater trend for manufacturing companies is using a DRaaS solution for at least a subset of their DR needs. (Related: Still Not Sold on the Advantages of Cloud Solutions for IBM Power Systems? Keep Reading.) In fact, DRaaS is among the fastest growing cloud-based service in the market today. Here’s a closer look at how that’s playing out in the manufacturing sector:
A Shifting Mindset
Along with the widespread acceptance of cloud solutions, the fast-growing DRaaS market can also be attributed to a more strategic mindset in how manufacturing businesses are thinking about their IT environments. DR was once a question of “What will it cost me to recover and rebuild?” Today, the notion of DR has evolved to reflect a more proactive mentality, with businesses now asking, “What’s it going to cost me if I CAN’T recover my systems?” and “What’s the true cost of that disruption to my customers and my business?”
There’s much to think about when it comes to implementing DR for your company, so in this section, we’ll break down some of the key terms, elements and pitfalls that surround a DR program.
DR and High Availability (HA)
While they often go hand in hand, it’s important to make the distinction between DR and High Availability (HA). By definition, disaster recovery is an area of security that aims to protect and recover your IT infrastructure in the event of a human or natural disaster.
A DR program, then, is a pre-planned, documented approach of policies and procedures. It ensures business continuity in the face of disruption for your IT infrastructure that supports your mission-critical business systems.
High Availability refers to the technology needed to minimize IT disruptions by ensuring continuity when critical parts of your environment are not available. HA solutions minimize downtime and data loss through replication: data is replicated on an environment that exists in a separate geographic location. With an HA solution, as changes are made on a production system, they are replicated on a back-up system in near-real-time. That means, if something were to happen to your production system, such as a fire or flood, an HA solution would be able to initiate a “failover” where your HA system assumes the role of your production system.
Together, HA/DR are critical components that ensure data integrity and business continuity around the clock.
|
Read more about how High Availability fits into your IBM i Disaster Recovery plan – check out this related article. |
Recovery Point Objective & Recovery Time Objective
How long can a manufacturing company’s system be down before your business is seriously impacted? Recovery time objective (RTO) is an organization’s best measure of this. By definition, RTO is the desired duration of time within which a business process must be restored after a disruption to avoid unacceptable consequences to business continuity. In general, the shorter your RTO, the more robust your DR plan will need to be.
In the event of a disaster that leads to downtime, systems designers will aim to revert to a recovery point objective (RPO), which is the point in time you’d like to go back to and retrieve your data. In the most simplified terms, if your business had a disaster two hours ago, your desired RPO would be the moments that were immediately prior to that two-hour mark.
Here are some key factors that organizations determine an optimal RTO and RPO:

These questions demand a careful, coordinated approach – and it’s critical to note that this is not just a task for your IT team. Your approach to DR should involve key business stakeholders throughout your manufacturing firm. (In the section that follows, How to Create a Top-Down DR Plan, we’ll take a deep drive on how to effectively do this.)
Keep In Mind These RTO Pitfalls
With RTO and RPO serving as major components of DR, manufacturing companies should be aware of a mistake that we see time and time again: in general, RTO estimates are too high.
Why? Too often companies approach RTO from an internal perspective. Businesses leaders assess their tolerance for downtime based on what’s happening “inside their own walls,” looking to their company’s systems, critical applications and internal processes to arrive at an estimate on what their tolerance is. What’s missing from that approach is customers. Customer impact and customer attrition are critical parts of this equation that are often overlooked.
When thinking about RTO, ask the following questions and you’re likely to realize your tolerance for downtime is far less.
Again, by creating a top-down DR plan that starts with your business requirements—not your applications—your company can gain a more reasonable and comprehensive understanding of downtime tolerances. Fortunately, we’ve seen the needle move in the right direction in general, with more manufacturing companies recognizing the importance of realistic RTO assessments.
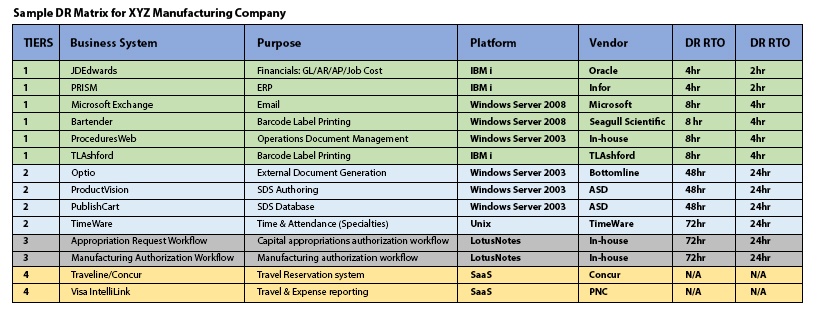
In this section, we’ll offer strategies to help create a DR that’s sufficient for your specific manufacturing organization. Remember, a DR plan is essentially a prioritized set of policies and procedures that will enable you to continually do business in the event of a disaster or system outage. A “top-down” DR program then, as we’re referring to here, should start with an assessment of your business requirements. It should ultimately yield a matrix of business applications showing downtime tolerances, solutions and associated costs on a per-application basis. The following section discusses each of these factors and how they all work together.
Downtime Assumptions
In the event of a disaster, which processes are most vital to your operations? How quickly will those supporting business applications need to be recovered? When thinking about DR, these questions are too often answered through assumptions. Business often believe 24-48 to be acceptable downtime for a given application—but rarely are those assumptions tested for accuracy.
|
Critical Tip: Ditch your downtime assumptions and keep an open mind! It’s nothing personal, but important to note that as business leaders approach DR from the top down, more often than not they will find their previous assumptions to be incorrect. |
With a strategic DR approach that includes the following steps, you can take a more realistic and strategic approach. And that starts with prioritizing your business processes.
1: Prioritize Business Processes
What are your mission-critical business processes? Which ones are the most important to keep your business going? For example, your “Tier 1” processes are those which cannot stop even for a short period of time, such as your customer-facing systems or order shipping systems. These processes are likely to require a mirroring solution that gives your company near-immediate recovery.
A Tier 2 process, on the other hand, is one that may not need to have immediate recovery. Why? Customers probably will not feel the impact right away and you can continue to do business when that process goes down. A Tier 3 business process, then, may be one that is important to employees and but is not essential to running your business… and so on and so forth. To assess your processes and assign these priorities in this way, you’ll need to do the following:
This analysis will essentially form the foundation of your DR plan and inform other criteria in your DR matrix, such as solutions and testing.
2: Assess Downtime Tolerances
At the same time you’re evaluating and prioritizing your business requirements, you will need to assign downtime tolerances for your business applications.
3: Factor in solutions and cost.
Given our integrated IT environments, downtime costs can be far reaching. Customers are not always patient. If your manufacturing firm is down for a few days, delayed business can mean lost business – and the revenue lost during that time must be considered in your DR plan.
Downtime costs, of course, extend beyond revenue lost. Be sure you factor in soft costs as well. For example, in the event you must revert to a manual process, what are the costs associated with having a less efficient workforce? Additionally, what costs are incurred not just during but after downtime? Ask questions such as:
It’s a good idea to note that determining the true cost of downtime is perhaps the most difficult aspect of disaster recovery. Downtime costs are unique to your specific business. They cannot be measured in a standardized way, nor is there a one-size-fits-all solution. Whether it’s a simple solution or a sophisticated one, a solution that’s driven by your business requirements is the best-fit choice for your organization.
4: Test Your Top-Down Design
Ultimately, your DR matrix rolls up each of these considerations into a DR plan that shows how each piece comes together: your business applications, each with an acceptable downtime tolerance, a solution and associated cost. Now it’s time to test through simulation. Testing, however, is another area of DR that’s commonly subject to pitfalls.
So where to most companies go wrong? Too often, applications are tested without considering connections and interdependencies, or the downstream/upstream effects. When considering a testing or back-up plan, many companies will start by looking at their core ERP systems, believing that if they have a plan to get their main systems up and running, they’ll be ok.
But as we know, business processes today rely on outside systems. From Windows servers in data centers, to cloud-based systems, to banking systems, to freight company systems… there are far more dependencies between interfaces and integrations than a cursory test (or a core system test) could ever account for. Instead, you can do the following:
Finally, keep in mind that failed tests are often documented but then nothing is done to correct them. Remember to be honest and keep an open mind about your results.
If you would like to take an even deeper dive on any of these steps, and learn how they have applied to other manufacturers, you can download our recorded webinar.
